
В современном мире практически любому бизнесу нужен веб-сайт. Если вы это понимаете и не готовы тратить личное время на изучение, создание, разработку или поиск исполнителей, то самый быстрый способ получить качественный сайт в короткие сроки — обратиться к автору этого блога за помощью.
Любая страница на сайте может быть открыта или закрыта для индексации поисковыми системами. Если страница открыта, поисковая система добавляет ее в свой индекс, если закрыта, то робот не заходит на нее и не учитывает в поисковой выдаче.
При создании сайта важно на программном уровне закрыть от индексации все страницы, которые по каким-либо причинам не должны видеть пользователи и поисковики.
К таким страницам можно отнести административную часть сайта (админку), страницы с различной служебной информацией (например, с личными данными зарегистрированных пользователей), страницы с многоуровневыми формами (например, сложные формы регистрации), формы обратной связи и т.д.
Пример:
Профиль пользователя на форуме о поисковых системах Searchengines.
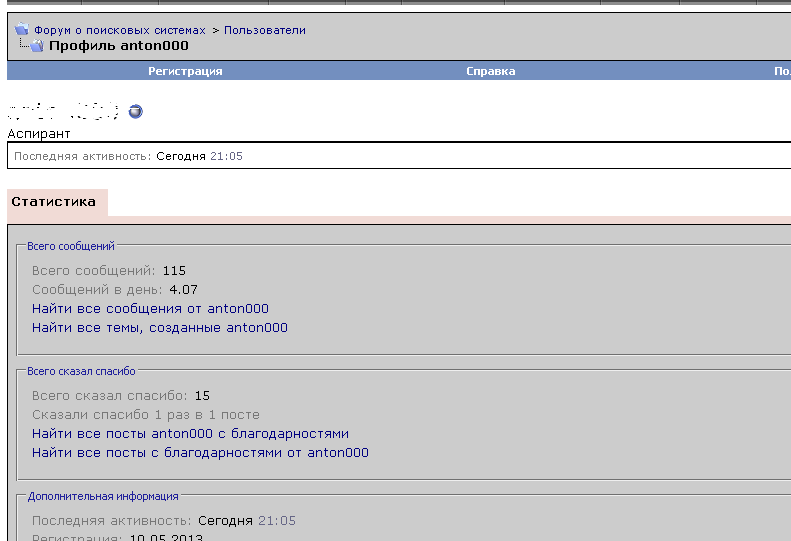
Обязательным также является закрытие от индексации страниц, содержимое которых уже используется на других страницах.Такие страницы называются дублирующими. Полные или частичные дубли сильно пессимизируют сайт, поскольку увеличивают количество неуникального контента на сайте.
Пример:
Типичный блог на CMSWordPress, который содержит дубли.http://reaktivist.ru/ — главная страница.
http://reaktivist.ru/category/liniya-zhizni — страница категории.
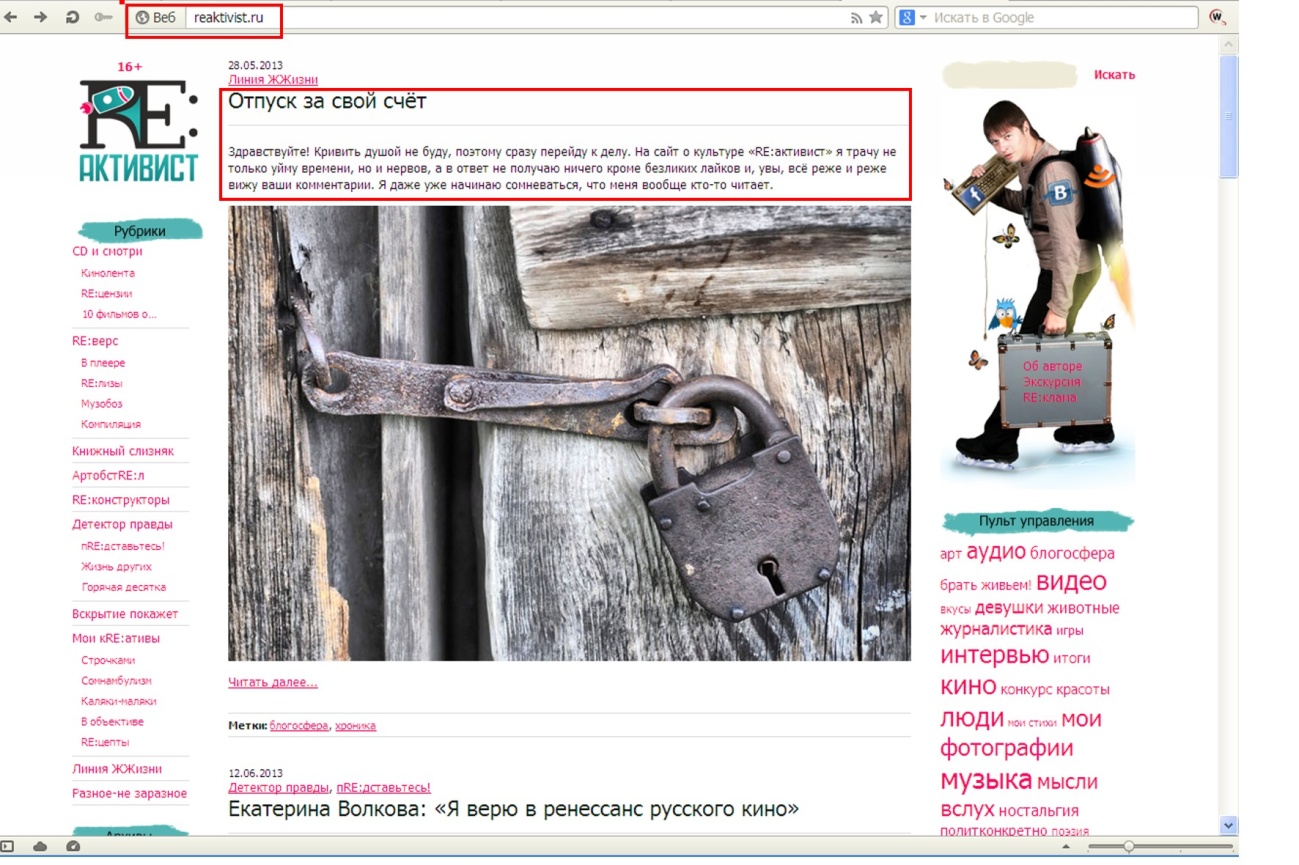
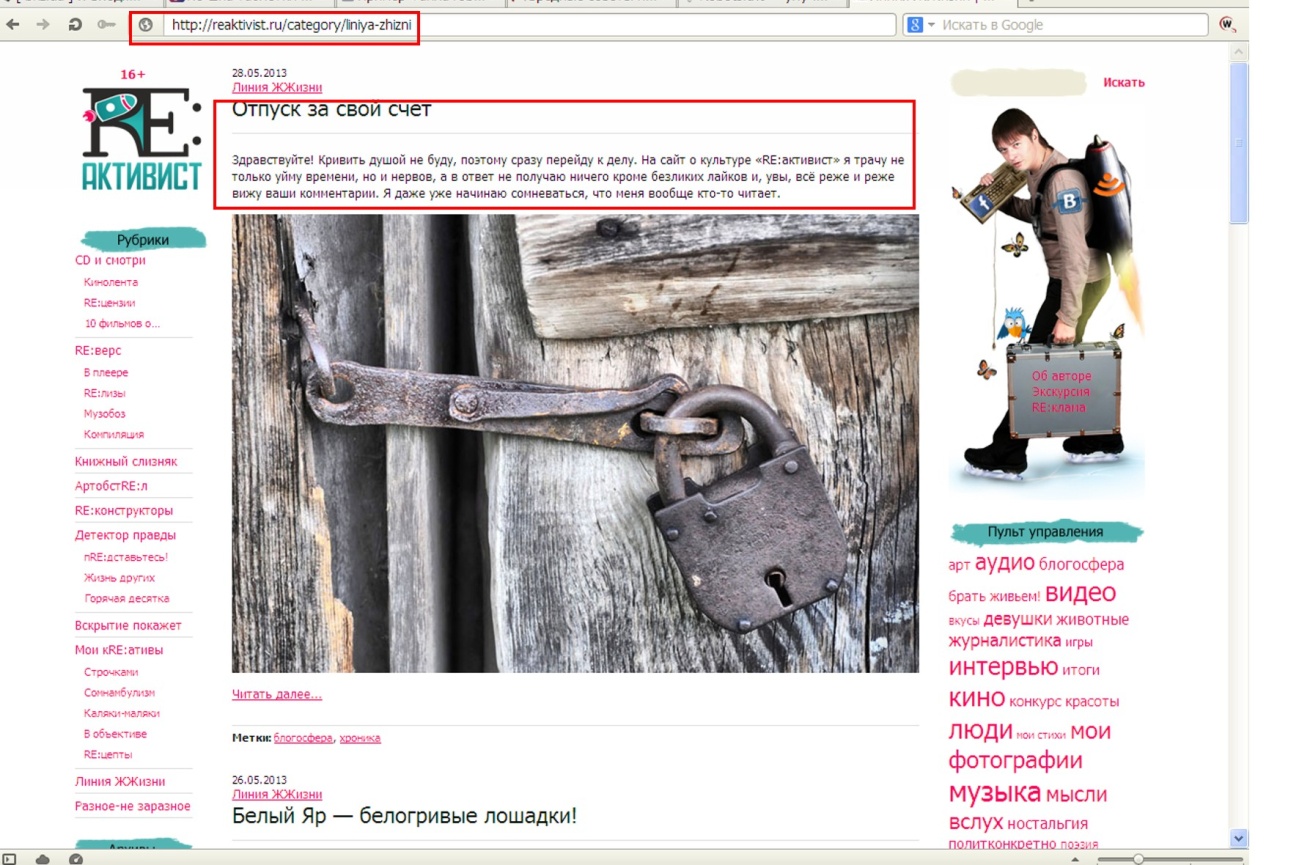
Как видим, контент на обеих страницах частично совпадает. Поэтому страницы категорий на WordPress-сайтах закрывают от индексации, либо выводят на них только название записей.
То же самое касается и страниц тэгов– такие страницы часто присутствуют в структуре блогов на WordPress. Облако тэгов облегчает навигацию по сайту и позволяет пользователям быстро находить интересующую информацию. Однако они являются частичными дублями других страниц, а значит – подлежат закрытию от индексации.
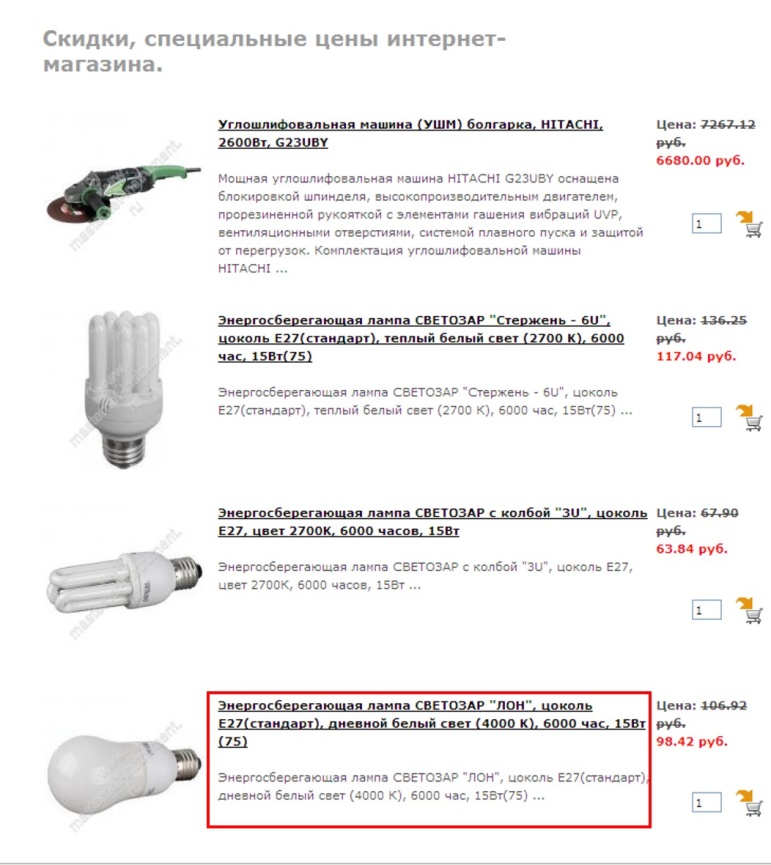
Еще один пример – магазин на CMS OpenCart.
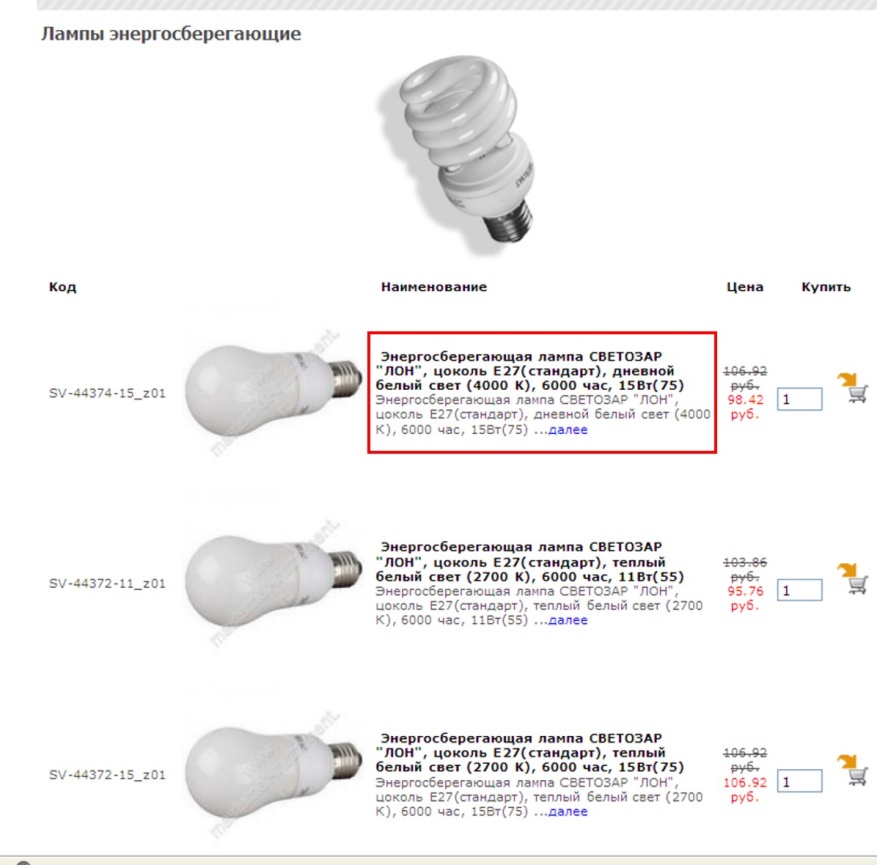
Страница категории товаров http://www.masternet-instrument.ru/Lampy-energosberegajuschie-c-906_910_947.html.
Страница товаров, на которые распространяется скидка http://www.masternet-instrument.ru/specials.php.
Данные страницы имеют схожее содержание, так как на них размещено много одинаковых товаров.
Особенно критично к дублированию контента на различных страницах сайта относится Google. За большое количество дублей в Google можно заработать определенные санкции вплоть до временного исключения сайта из поисковой выдачи.
Мы рекомендуем закрывать страницу от индексации, если она содержит более 40 % контента с другой страницы. В идеале структуру сайта нужно создавать таким образом, чтобы дублирования контента не было вовсе.
Примечание:
Для авторитетных сайтов с большим количеством страниц и хорошей посещаемостью (от 3000 человек в сутки) дублирование не столь существенно, как для новых сайтов.
Еще один случай, когда содержимое страниц не стоит «показывать» поисковику – страницы с неуникальным контентом. Типичный пример — инструкции к медицинским препаратам в интернет-аптеке. Контент на странице с описанием препарата http://www.piluli.ru/product271593/product_info.html неуникален и опубликован на сотнях других сайтов.
Сделать его уникальным практически невозможно, поскольку переписывание столь специфических текстов – дело неблагодарное и запрещенное. Наилучшим решением в этом случае будет закрытие страницы от индексации, либо написание письма в поисковые системы с просьбой лояльно отнестись к неуникальности контента, который сделать уникальным невозможно по тем или иным причинам.
Как закрывать страницы от индексации
Классическим инструментом для закрытия страниц от индексации является файл robots.txt. Он находится в корневом каталоге вашего сайта и создается специально для того, чтобы показать поисковым роботам, какие страницы им посещать нельзя. Это обычный текстовый файл, который вы в любой момент можете отредактировать. Если файла robots.txt у вас нет или если он пуст, поисковики по умолчанию будут индексировать все страницы, которые найдут.
Структура файла robots.txt довольно проста. Он может состоять из одного или нескольких блоков (инструкций). Каждая инструкция, в свою очередь, состоит из двух строк. Первая строка называется User-agent и определяет, какой поисковик должен следовать этой инструкции. Если вы хотите запретить индексацию для всех поисковиков, первая строка должна выглядеть так:
User-agent: *
Если вы хотите запретить индексацию страницы только для одной ПС, например, для Яндекса, первая строка выглядит так:
User-agent: Yandex
Вторая строчка инструкции называется Disallow (запретить). Для запрета всех страниц сайта напишите в этой строке следующее:
Disallow: /
Чтобы разрешить индексацию всех страниц вторая строка должна иметь вид:
Disallow:
В строке Disallow вы можете указывать конкретные папки и файлы, которые нужно закрыть от индексации.
Например, для запрета индексации папки images и всего ее содержимого пишем:
User-agent: *
Disallow: /images/
Чтобы «спрятать» от поисковиков конкретные файлы, перечисляем их:
User-agent: *
Disallow: /myfile1.htm
Disallow: /myfile2.htm
Disallow: /myfile3.htm
Это – основные принципы структуры файла robots.txt. Они помогут вам закрыть от индексации отдельные страницы и папки на вашем сайте.
Еще один, менее распространенный способ запрета индексации – мета-тэг Robots. Если вы хотите закрыть от индексации страницу или запретить поисковикам индексировать ссылки, размещенные на ней, в ее HTML-коде необходимо прописать этот тэг. Его надо размещать в области HEAD, перед тэгом <title>.
Мета-тег Robots состоит из двух параметров. INDEX – параметр, отвечающий за индексацию самой страницы, а FOLLOW – параметр, разрешающий или запрещающий индексацию ссылок, расположенных на этой странице.
Для запрета индексации вместо INDEX и FOLLOW следует писать NOINDEX и NOFOLLOW соответственно.
Таким образом, если вы хотите закрыть страницу от индексации и запретить поисковикам учитывать ссылки на ней, вам надо добавить в код такую строку:
<meta name=“robots” content=“noindex,nofollow”>
Если вы не хотите скрывать страницу от индексации, но вам необходимо «спрятать» ссылки на ней, мета-тег Robots будет выглядеть так:
<metaname=“robots” content=“index,nofollow”>
Если же вам наоборот, надо скрыть страницу от ПС, но при этом учитывать ссылки, данный тэг будет иметь такой вид:
<meta name=“robots” content=“noindex,follow”>
Большинство современных CMS дают возможность закрывать некоторые страницы от индексации прямо из админ.панели сайта. Это позволяет избежать необходимости разбираться в коде и настраивать данные параметры вручную. Однако перечисленные выше способы были и остаются универсальными и самыми надежными инструментами для запрета индексации.
добрый день, а можно ли скрыть страницу от поисковиков, используя в панеле справа
Видимость: Защищено паролем, тоесть защитить паролем? спасибо за ответ